August 13, 2019 By BlueAlly

One of the biggest challenges for organizations is buying and implementing the right tooling to empower their security teams. In general, most organizations have a history of inadvertently buying ineffective tooling or struggling to get value from existing tooling due to noise or complexity. And while organizations such as Gartner provide product guidance, this can often be too high level and not based on real-world benchmarking.
To help provide organizations with a more detailed analysis of tooling in 2017 [1], MITRE launched a program to evaluate EDR vendors against the MITRE ATT&CK framework to effectively offer a publicly available impartial benchmark. The initial results were released in 2018 and give a great overview of the kinds of telemetry, alerts, interface and output you get from each product or service listed.
The assessment was based on a real-world threat group APT3 and provided a rich set of detection cases to measure against covering all major areas of the cyber kill chain. However, it did not factor in at all how effective in a real-world environment this would be, nor did it cover any aspects of responding to attacks. So although the evaluation is a useful starting point, it should form just one aspect of how you assess an EDR product.
In this article we’ll delve into the MITRE testing methodology and compare this against what matters in the real world to give some useful tips for analyzing the evaluation results.
An EDR Product Assessment
The Round 1 MITRE evaluation is essentially a product assessment that is focused on measuring EDR detection capabilities in a controlled environment with the main assessment criteria being telemetry and detections. The output is a list of test cases and results for each, focusing mainly on detection specificity and time to receive the information. Taking a simplified approach like this helps break down a complex problem space like detection into something more manageable. But does this overly simplify the problem?
Often, in the world of detection it’s not finding the “bad things” that matter, but excluding legitimate activity so your team can more effectively spot anomalous activity. By testing in a noise-free environment vendors are able to claim to “detect” test cases that would have likely been hidden by noise in the real world. MITRE clearly note this as a limitation but it’s not all that obvious when reviewing results.
Going beyond the product itself, key areas like the people driving the tool and process/workflow are also noticeably absent from the test and are often more important than the tool itself. As such we’d recommend taking a holistic approach, using the MITRE evaluation as a starting point but remaining aware of its limitations and instead asking your own questions. For example:
- What are the false positive rates like in the real-world?
- Can you demonstrate capabilities that either limit noise or help draw attention to specific activity that closely matches legitimate activity?
- Can you demonstrate a real-world end-to-end investigation? From a threat hunting-based detection, to investigation, to time-lining and response?
- Can you issue response tasks in order to retrieve forensic data from the machine?
- Can you contain and battle an attacker off the network?
- Is my detection team technically capable of driving the tool and available 24/7/365?
- Could you benefit from a managed service and if so can they demonstrate they are able to detect advanced attacks?
But what can you learn from the existing results? And how should you interpret them?
Each vendor has their own set of results that consist of roughly 100 different test cases, each with an associated Description, Technique ID, Detection Type, and Detection Notes. The first thing to note is that this is a technical assessment with technical results and no high-level scoring mechanism so you may need to ask your technical team members (or an external party) for guidance. We’ve included an example result below.
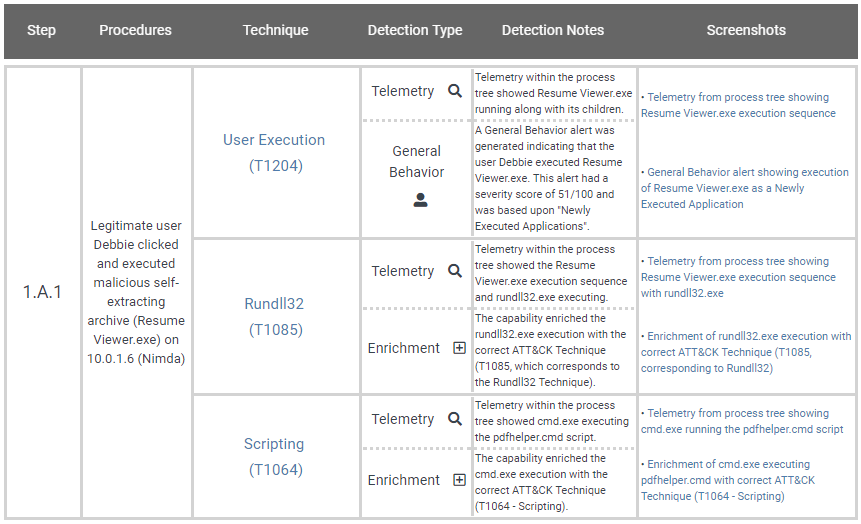
The test results give some great technical detail, but no obvious score.
The most relevant fields here are the “Detection Type” and “Detection Notes” as they explain how the vendor performed. Together they give a summary of essentially whether the vendor logged any associated telemetry and whether there were any alerts/detections related to the activity.
In the following sections we’ll look at how you can assess the importance of both “Telemetry” and “Detections”.
How to measure telemetry
The biggest pre-requisite for any kind of detection is having the data to analyze it in the first place. Most EDR providers will collect real-time telemetry for process data, file data, network connections and services, registry or persistence data, which cover a large number of attacker actions. But what are the key factors to look out for here?
Collected Data – Looking at the test cases you’ll see most products successfully collected telemetry for nearly every test case. One area where quite a few products were caught out was the Empire section where the actors disable PowerShell logging. Only a subset of products detected this activity. Outside of MITRE you’ll find more advanced products will also collect data associated with memory anomalies and data for WMI and .NET activity which can help detect more cutting-edge attacks.
Timing – Response times matter and the MITRE results provide a measure for how long it might take for data/alerts to be returned to you from an endpoint. MITRE assign a “delayed” tag to anything that takes more than roughly 30 minutes or so. While faster data processing is a good thing, the reality is that most real-world breaches will take minutes or hours to detect and contain (with an industry average of months to years). So we’d recommend focusing less on the time to receive data and more on whether you are able to detect the attack at all and how long it takes you to contain it.
Quality – The MITRE evaluation can help you understand if a product collects basic data for the specific test cases; it won’t, however, help you confirm that the product gives you the necessary context to complete an investigation (this comes back to the isolated product test vs real world issue). For example, a process event will usually contain the path to what executed, but does it also show you the hash, certificate information, parent processes, and child processes? This is not something MITRE measures.
Retention – One subtle point with the MITRE evaluation is that testing and assessment are performed immediately after each other so retention isn’t a factor. In the real world, retention is a huge problem as EDR datasets can be very large making long time storage costly and technically challenging. As a business it’s important to clarify how long each of the datasets will be stored for, as this can have a financial, regulatory and operational impact. For example, if you don’t have a 24/7 team and something were to happen on the weekend, the data could be gone by Monday.
Understanding Detection Types
Automated alerting allows your team to scale your detection efforts and increase your reliability of detecting known indicators. Detections are a key component of the MITRE evaluation, with detection quality captured by classifying alerts as enrichments, general behaviors or specific behaviors. In general, the more specific the indicator the better, as they create fewer alerts.
Do remember though that detections and alerts are just one component in your detection approach and should not be relied on as a single approach because:
- Static detection rules can bypassed Attackers are continually innovating and have a long history of bypassing security products – either by using different forms of obfuscation or never-seen-before techniques that existing tools simply can’t identify as malicious. Assume your rules can and will be bypassed.
- Alerts are often false positive prone One of the biggest challenges when handling alerts are the false positives, there is a huge difference between whether alerts will be acted upon if they happen in their hundreds or thousands a day, vs extremely high-fidelity alerts that are meaningful enough to have a big red alarm go off. Aside from missing attacks, alert fidelity can also impact team efficiency and lead to alert fatigue. Fidelity is unfortunately not something that is captured in Round 1 of the MITRE evaluation and is actually extremely difficult to measure effectively outside a real-world enterprise scale network. Therefore it is worth taking any MITRE detection results with a big pinch of salt.
- Alerts are “reactive” instead of “proactive” When used correctly alerts can help you reliably spot the easy stuff and improve your response times. The risk with taking an alert-based approach is that it can create a reactive culture within your team leading to complacency and a false sense of security. Finding the right balance between reactive alert-based detection and proactive research driven threat hunting will help you catch the anomalies that tools/alerts will often miss.
Comparing solutions
Although MITRE don’t score solutions, they do provide a comparison tool to help you easily see for each use-case how each solution performed.
It’s useful to take a holistic approach when comparing results, giving equal weighting to telemetry, detection, and how quickly results are returned (low number of “delayed” results), as each of these aspects bring different benefits to security teams. For the detection and managed service components you want to make sure that adequate information is provided to enable your team to respond to any notifications.

Forester have previously released a scoring tool for MITRE. While an interesting approach, the results for this tool are heavily weighted towards detections and – as mentioned already – using detections as your primary evaluation criteria is not a good way of measuring the overall effectiveness of an EDR tool. What matters most in a real-world breach is having the right data, analytics, detections, response features, and – most importantly – a capable team to drive any tool.
The MITRE Evaluation
The MITRE evaluation is a great step forward for the security industry, bringing some much needed visibility and independent testing to the EDR space. MITRE themselves should be applauded for their efforts, as fairly and independently comparing solutions in such a complex problem space is very challenging.
There are definitely some limitations in Round One due to the focus on telemetry/detections and lack of real-world noise, workflow, incident response or managed service testing. It’s hoped that Round 2 starting in late 2019 will bring some improvements in these areas, although it’s possible this type of assessment may never get to the point where it removes the need for organizations to do their own testing.
In the short term though we are excited to announce that F-Secure Countercept has just completed the Round 1 MITRE evaluation and we will be posting the results when they are ready. To help you decide if F-Secure Countercept best meets your cyber security needs, we will include a technical guide as to how our features performed.
References
[1] https://medium.com/mitre-attack/first-round-of-mitre-att-ck-evaluations-released-15db64ea970d
[2] https://www.endgame.com/blog/technical-blog/putting-mitre-attck-evaluation-context
